









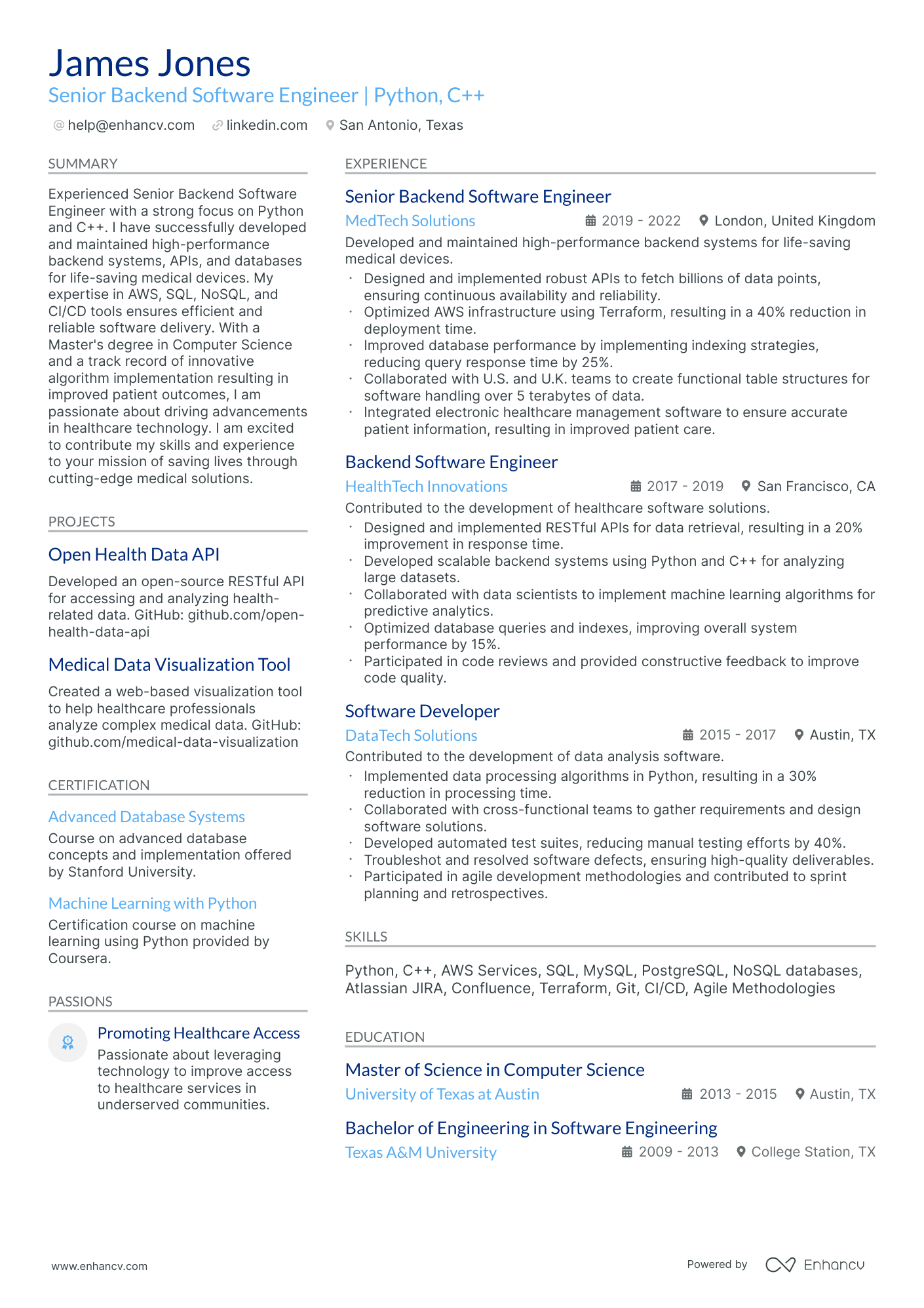

A specific challenge faced by a senior data engineer is tailoring their resume to highlight the advanced technical skills and project management experience that differentiate them from junior-level engineers. Our guide can assist in addressing this challenge by providing targeted examples and strategies for effectively presenting these specialized skills and experiences, helping to distinguish your application in a competitive job market.
Dive into this guide to uncover:
- Top-tier senior data engineer resume samples that have successfully landed candidates in leading companies.
- Strategies to direct recruiters' focus towards your standout experiences, notable achievements, and pivotal skills.
- Guidance on crafting resume sections that align closely with the vast majority of job specifications.
- Insights on harmonizing your senior data engineer technical prowess with your distinct personality, setting you apart from the competition.

Recommended reads:
crafting a stellar senior data engineer resume format
Navigating the maze of resume formatting can be challenging. But understanding what recruiters prioritize can make the process smoother.
Wondering about the optimal format, the importance of certain sections, or how to detail your experience? Here's a blueprint for a polished resume:
- Adopt the reverse-chronological resume format. By spotlighting your latest roles upfront, you offer recruiters a snapshot of your career trajectory and recent accomplishments.
- Your header isn't just a formality. Beyond basic contact information, consider adding a link to your portfolio and a headline that encapsulates a significant achievement or your current role.
- Distill your content to the most pertinent details, ideally fitting within a two-page limit. Every line should reinforce your candidacy for the senior data engineer role.
- To preserve your resume's layout across different devices and platforms, save it as a PDF.
Each market has its own resume standards – a Canadian resume layout may differ, for example.
Upload your resume
Drop your resume here or choose a file. PDF & DOCX only. Max 2MB file size.

Pro tip
If you don't happen to have that much relevant experience for the role, you could select a different format for your resume. Popular choices include:
- functional skill-based resume format - that puts the main focus on your skills and accomplishments;
- hybrid resume format - to get the best of both worlds with your senior data engineer experience and skills.

Don't forget to include these six sections on your senior data engineer resume:
- A header for your contact details and a summary that highlight your alignment with the senior data engineer job you're applying for
- An experience section that explains how you apply your technical and personal skills to deliver successful results
- A skills section that further highlights how your profile matches the job requirements
- An education section that provides your academic background
- An achievements' section that mentions any career highlights that may be impressive, or that you might have missed so far in other resume sections
What recruiters want to see on your resume:
- Experience with data pipelines: Recruiters look for demonstrated experience in building, testing, and maintaining highly scalable and robust data pipelines.
- Proficiency in programming languages: Expertise in SQL, Python, Java or other similar languages is crucial for a senior data engineer role. Demonstrated skills in optimizing data retrieval and developing algorithms are important.
- Knowledge of Big Data tools: Experience with big data processing frameworks and tools such as Hadoop, Spark, Kafka is an important factor that recruiters prioritize.
- Database management expertise: Knowledge about database systems (both SQL and NoSQL), including designing, implementation, and handling is considered significant.
- Data security and governance: As a senior role, understanding data laws and regulations, as well as ensuring data integrity and security is key. The ability to handle sensitive information responsibly is prioritized by recruiters.
Recommended reads:
Detailing your relevant experience on your senior data engineer resume
Showcase your credibility in the resume experience section. For an effective senior data engineer resume:
- Highlight measurable achievements.
- Scan the job advert for keywords and integrate them throughout your experience section.
- Emphasize your technical proficiencies and how you've applied them in various roles.
- Keep it simple: mention your responsibility, relevant skills, and the outcomes.
- Use this section to convey your unique value, soft skills, feedback received, and the type of company culture you thrive in.
Top professionals ensure their experience section offers a captivating look at their expertise. Check out our sample senior data engineer resumes for guidance.
- Led a team of data engineers to design and implement scalable data pipelines, resulting in a 30% reduction in data processing time.
- Developed ETL workflows using Apache Airflow to automate data ingestion from multiple sources, ensuring timely and accurate data availability.
- Optimized SQL queries and database performance, improving query response time by 40%.
- Implemented real-time data streaming architecture using Apache Kafka, enabling efficient processing of high-volume data streams.
- Collaborated with cross-functional teams to deliver data solutions aligned with business requirements.
- Managed AWS infrastructure, implementing cost-saving measures and ensuring high availability of data systems.
- Designed and developed a distributed data processing system using Hadoop, handling terabytes of data to support advanced analytics.
- Created data models and schema designs for data warehouses, enabling efficient data retrieval and analysis.
- Implemented data quality frameworks and automated data validation processes, reducing data inconsistencies by 25%.
- Collaborated with data scientists to integrate machine learning models into production systems for predictive analytics.
- Led the migration of on-premises data infrastructure to the cloud, resulting in increased scalability and reduced operational costs.
- Provided technical guidance and mentorship to junior data engineers, fostering a culture of continuous learning.
- Developed and maintained a real-time data processing pipeline using Apache Flink, enabling near-instantaneous data analysis.
- Implemented data governance policies and ensured compliance with data privacy regulations (GDPR, CCPA).
- Collaborated with data scientists to build scalable machine learning pipelines for predictive modeling and anomaly detection.
- Optimized data storage and retrieval mechanisms, reducing storage costs by 20% while improving query performance.
- Designed and implemented data security measures, including encryption at rest and in transit, ensuring data confidentiality.
- Managed the deployment and monitoring of data applications on Kubernetes clusters, ensuring high availability and fault tolerance.
- Architected and implemented a data lakes solution using AWS S3 and Apache Spark, enabling efficient storage and processing of large-scale data.
- Led a team in building scalable data pipelines using Python and Java, resulting in improved data delivery times by 50%.
- Implemented data quality checks and automated anomaly detection algorithms, reducing data errors by 40%.
- Collaborated with software engineers to integrate data platforms with external systems, enabling seamless data exchange.
- Developed real-time monitoring and alerting systems for data infrastructure, ensuring timely issue resolution.
- Mentored junior data engineers and conducted training sessions on emerging technologies and best practices.
- Designed and implemented a scalable data architecture using cloud-native technologies (AWS, Azure), resulting in improved data processing efficiency.
- Built data pipelines using Apache Beam and Google Dataflow, handling large volumes of streaming and batch data.
- Implemented data orchestration frameworks like Apache NiFi to streamline data workflows, reducing manual intervention by 60%.
- Collaborated with data scientists to operationalize machine learning models for real-time decision making and personalization.
- Optimized data storage and retrieval processes, leveraging columnar databases and compression techniques for efficient resource utilization.
- Led the evaluation and adoption of new data technologies to enhance data engineering capabilities.
- Developed scalable data ingestion frameworks using Apache Kafka and Apache Flume, enabling near-real-time data processing.
- Designed and implemented fault-tolerant data pipelines using Hadoop ecosystem (HDFS, Hive, Pig) for big data analytics.
- Performed data profiling and analysis to identify data quality issues and implemented remediation strategies.
- Collaborated with cross-functional teams to define data requirements and design data models to support business insights.
- Optimized data transformation processes using Apache Spark, resulting in a 30% improvement in data processing time.
- Conducted performance tuning on database systems and SQL queries to enhance query response times.
- Architected and developed a cloud-based data platform using AWS services (S3, Glue, Athena) for efficient data storage and processing.
- Implemented streaming data pipelines using Apache Kafka and Apache Flink, enabling real-time analytics and event-driven processing.
- Designed and implemented data governance policies and ensured compliance with industry regulations (HIPAA, PCI-DSS).
- Collaborated with cross-functional teams to define data requirements and ensure data consistency across systems.
- Developed and maintained scalable data infrastructure using infrastructure-as-code (Terraform) and configuration management tools.
- Provided technical leadership and guidance to junior data engineers, fostering a culture of innovation and continuous improvement.
- Built and maintained data pipelines using Apache NiFi and Apache Kafka, facilitating efficient data ingestion from various sources.
- Designed and implemented data warehousing solutions using Snowflake and Redshift, optimizing data storage and query performance.
- Developed ETL processes and orchestrated data workflows using Python and Apache Airflow, ensuring data integrity and timely availability.
- Collaborated with data scientists to implement machine learning models on production systems for fraud detection and customer segmentation.
- Optimized data processing algorithms, reducing data processing time by 30% and enabling faster insights generation.
- Led the deployment and management of containerized data applications on Kubernetes clusters.
- Developed scalable data architectures using traditional RDBMS and NoSQL databases, ensuring efficient data storage and retrieval.
- Implemented batch and near-real-time data integration processes using ETL tools (Informatica, Talend) and message queuing systems.
- Collaborated with business stakeholders to define data requirements and design data models for reporting and analytics purposes.
- Led the development of data visualization dashboards using Tableau, providing actionable insights to business users.
- Performed data profiling and cleansing activities to ensure data quality and accuracy.
- Conducted performance tuning on data processing jobs and database queries to optimize system performance.
- Built and maintained scalable data pipelines using Apache Kafka and Apache Storm, handling high-throughput data streams.
- Designed and implemented distributed data processing frameworks using Apache Spark, enabling faster data analysis.
- Developed data modeling strategies and implemented data warehouses using SQL and NoSQL databases.
- Collaborated with data scientists to develop machine learning solutions for predictive analytics and recommendation systems.
- Optimized data storage and retrieval mechanisms, implementing indexing strategies and partitioning schemes for improved performance.
- Provided technical guidance and expertise in data engineering best practices to cross-functional teams.
Quantifying impact on your resume
<ul>
Strategies for candidates with limited resume experience
Lack of extensive experience doesn't mean you can't make a strong impression. Here's how:
- Thoroughly understand the role's requirements and reflect them in key resume sections.
- Highlight transferable skills and personal attributes that make you a valuable candidate.
- Use the resume objective to articulate your growth vision within the company.
- Emphasize technical alignment through relevant certifications, education, and skills.
Remember, your resume's primary goal is to showcase how you align with the ideal candidate profile. The closer you match the job requirements, the higher your chances of securing an interview.
Recommended reads:
Pro tip
Boost your resume by focusing on the practical aspects of each job requirement. While it's good to have job-related keywords on your resume, ensure they're backed by action verbs and quantifiable data. This gives recruiters a clear picture of your senior data engineer professional journey.
creating your senior data engineer resume skills section: balancing hard skills and soft skills
Recruiters hiring for senior data engineer roles are always keen on hiring candidates with relevant technical and people talents.
Hard skills or technical ones are quite beneficial for the industry - as they refer to your competency with particular software and technologies.
Meanwhile, your soft (or people) skills are quite crucial to yours and the company's professional growth as they detail how you'd cooperate and interact in your potential environment.
Here's how to describe your hard and soft skill set in your senior data engineer resume:
- Consider what the key job requirements are and list those towards the top of your skills section.
- Think of individual, specific skills that help you stand out amongst competitors, and detail how they've helped you succeed in the past.
- Look to the future of the industry and list all software/ technologies which are forward-facing.
- Create a separate, technical skills section to supplement your experience and further align with the senior data engineer job advert.
Find the perfect balance between your resume hard and soft skills with our two lists.
Top skills for your senior data engineer resume:
Apache Spark
Hadoop
SQL
Python
Kafka
AWS (Amazon Web Services)
ETL (Extract, Transform, Load)
Data Warehousing
NoSQL Databases (e.g., MongoDB, Cassandra)
Data Modeling
Problem Solving
Communication
Team Collaboration
Adaptability
Critical Thinking
Attention to Detail
Time Management
Project Management
Analytical Thinking
Creativity
Pro tip
When detailing your skills, align them with the job's requirements. Emphasize unique technical proficiencies and provide examples of your soft skills in action.
Highlighting certifications and education on your senior data engineer resume
Your academic achievements, including certifications and degrees, bolster your application. They showcase your skills and commitment to the field.
To effectively present these on your resume:
- Highlight significant academic achievements or recognitions relevant to the role.
- Be selective; prioritize the most relevant and impressive certifications.
- Include essential details: certificate/degree name, institution, graduation dates, and license numbers (if applicable).
- Present your academic background in reverse chronological order, emphasizing the most recent and relevant qualifications.
For further guidance, explore popular industry certifications.
Best certifications to list on your resume
Pro tip
If a particular certification is highly valued in the industry or by the company, consider highlighting it in your resume's headline.
Recommended reads:
best practices for your senior data engineer resume summary or objective
How do you know if you should include a resume summary or a resume objective?
- Resume summaries are ideal for senior data engineer professionals with more experience, who'd like to give a quick glimpse of their biggest career achievements in the top one-third of their resumes.
- On the other hand, resume objectives serve as a road map to the applicant's aspirations. Candidates use the objective as the North Star of their career (or, how they see themselves in the role in the next few years).
Both could be the perfect fit for your senior data engineer resume, depending on your experience.
Here's how candidates for the senior data engineer job structure their summaries and objectives.
Resume summary and objective examples for a senior data engineer resume
Four additional sections to consider for your senior data engineer resume
To give a fuller picture of who you are, consider adding these sections to your senior data engineer resume:
- Awards - to showcase your achievements.
- Interests - to share passions outside of work.
- Publications - to highlight your contributions to the field.
- Projects - to spotlight significant accomplishments, even those outside of traditional work settings.
Key takeaways
- Craft a senior data engineer resume that's easy to read and aligns with the role's requirements.
- The top third of your resume should clearly convey your unique value proposition for the senior data engineer role.
- Tailor your resume to the job, highlighting skills, achievements, and the tangible results of your efforts.
- Detail your certifications and technical skills to demonstrate proficiency with specific tools and technologies.
- The sections you choose should collectively present a comprehensive view of your professional expertise and personality.
