










One key challenge for an AWS data engineer may be showcasing their unique combination of coding, AWS cloud services, and data engineering competencies in a concise yet impactful manner. Our guide can assist by offering specific examples and templates on how to effectively highlight these multifaceted skills and experience, thereby making the resume more appealing to potential employers.
Dive into this guide to learn how to craft a AWS data engineer resume that offers recruiters a clear view of your career journey:
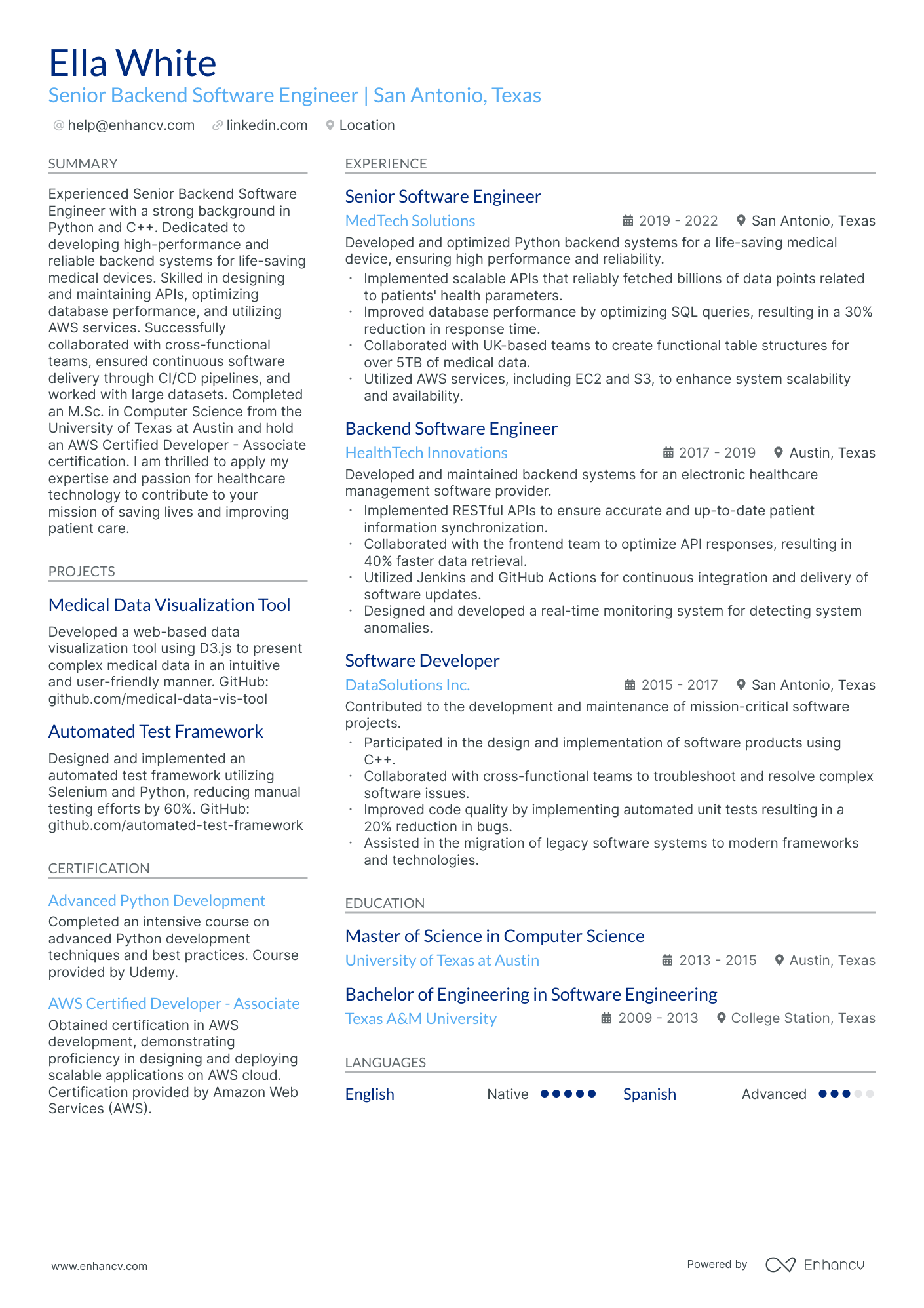
- Draw from our AWS data engineer resume samples, highlighting top skills, certifications, and more.
- Illuminate the potential impact you can bring to an organization through your resume summary and experience.
- Spotlight your unique AWS data engineer expertise, emphasizing tangible results and standout achievements.

Recommended reads:
crafting a stellar AWS data engineer resume format
Navigating the maze of resume formatting can be challenging. But understanding what recruiters prioritize can make the process smoother.
Wondering about the optimal format, the importance of certain sections, or how to detail your experience? Here's a blueprint for a polished resume:
- Adopt the reverse-chronological resume format. By spotlighting your latest roles upfront, you offer recruiters a snapshot of your career trajectory and recent accomplishments.
- Your header isn't just a formality. Beyond basic contact information, consider adding a link to your portfolio and a headline that encapsulates a significant achievement or your current role.
- Distill your content to the most pertinent details, ideally fitting within a two-page limit. Every line should reinforce your candidacy for the AWS data engineer role.
- To preserve your resume's layout across different devices and platforms, save it as a PDF.
Each market has its own resume standards – a Canadian resume layout may differ, for example.
Upload your resume
Drop your resume here or choose a file. PDF & DOCX only. Max 2MB file size.

Pro tip
Make sure your resume is ATS compliant and catches the recruiters' attention by tailoring your experience to the specific job requirements. Quantify and highlight why you're the best candidate for the role on the first page of your resume.

Essential sections for a standout senior attorney resume:
- The top section should combine your header—with accurate contact details—and a concise summary or objective that encapsulates your professional achievements.
- An experience section that chronicles your career trajectory and how each role contributed to your professional development.
- Highlight significant achievements that demonstrate the practical application of your skills, leading to tangible results.
- Include industry-recognized certifications to underscore your technical proficiency or interpersonal skills.
- Detail your educational background relevant to the field.
What recruiters want to see on your resume:
- Experience with AWS services: Recruiters look for experience with a range of AWS services such as S3, Redshift, RDS, and DynamoDB. Knowledge of services like EMR and Lambda is also highly valued.
- Data modeling and database design skills: Proficiency in conceptual, logical, and physical data modeling, ER diagrams, and database normalization is important.
- Data pipeline creation: Demonstrated experience creating and managing ETL pipelines using tools like AWS Glue or Apache Beam can set candidates apart.
- Scripting and programming languages: Experience with scripting languages like Python or Java, and specific SQL knowledge are crucial for dealing with large datasets.
- Knowledge of Big Data technologies: Understanding and working experience with Hadoop ecosystem, Spark, Hive or other big data technologies is often sought after by recruiters.
Recommended reads:
guide to your most impressive AWS data engineer resume experience section
When it comes to your resume experience, stick to these simple, yet effective five steps:
- Show how your experience is relevant by including your responsibility, skill used, and outcome/-s;
- Use individual bullets to answer how your experience aligns with the job requirements;
- Think of a way to demonstrate the tangible results of your success with stats, numbers, and/or percentages ;
- Always tailor the experience section to the AWS data engineer role you're applying for - this may sometimes include taking out irrelevant experience items;
- Highlight your best (and most relevant) achievements towards the top of each experience bullet.
You're not alone if you're struggling with curating your experience section. That's why we've prepared some professional, real-life AWS data engineer resume samples to show how to best write your experience section (and more).
- Designed and implemented scalable data pipelines on AWS using Glue, Lambda, and S3, resulting in a 50% reduction in data processing time.
- Developed ETL processes utilizing AWS EMR and Apache Spark to transform and load petabytes of data into a centralized data lake.
- Optimized AWS Redshift cluster performance by fine-tuning query execution plans, reducing query response time by 40%.
- Implemented real-time data streaming architecture using Kinesis Data Streams and Lambda, enabling near-instantaneous data analysis.
- Collaborated with cross-functional teams to design and build a data warehouse solution on AWS, facilitating efficient reporting and analytics.
- Built and maintained data pipelines using AWS Glue, transforming raw data into structured formats for further analysis.
- Implemented serverless architectures with AWS Lambda, reducing infrastructure costs by 30%.
- Developed and optimized SQL queries in AWS Redshift to support complex analytical requirements.
- Collaborated with data scientists to deploy machine learning models on AWS SageMaker, improving prediction accuracy by 20%.
- Migrated on-premises data infrastructure to AWS cloud, resulting in increased scalability and reduced maintenance efforts.
- Implemented data ingestion processes using AWS Glue, ensuring timely and accurate data delivery.
- Developed ETL workflows using AWS Data Pipeline, automating the extraction, transformation, and loading of data.
- Performed data modeling and schema design for AWS Redshift, optimizing query performance.
- Built real-time analytics solutions using AWS Kinesis and Apache Kafka, enabling instant insights into streaming data.
- Collaborated with cross-functional teams to design and implement a scalable data architecture on AWS.
- Designed and implemented data lakes on AWS S3, storing and processing large volumes of structured and unstructured data.
- Developed data ingestion frameworks using AWS Glue and Python, automating the extraction and transformation of diverse data sources.
- Optimized AWS Redshift performance through query optimization and workload management techniques, improving overall system efficiency.
- Implemented serverless data processing using AWS Lambda and Step Functions, reducing operational costs by 25%.
- Collaborated with data scientists to develop scalable machine learning pipelines using AWS SageMaker, resulting in improved model training time.
- Designed and implemented scalable data ingestion processes using AWS Glue, enabling efficient data retrieval and analysis.
- Developed and maintained ETL workflows using AWS Data Pipeline, ensuring the accuracy and timeliness of data transformations.
- Optimized database performance in AWS Redshift by tuning sort and distribution keys, resulting in a 30% improvement in query response time.
- Implemented real-time data streaming solutions using AWS Kinesis and Apache Flink, enabling immediate data insights for decision-making.
- Collaborated with software engineers to develop a custom analytics platform on AWS, providing self-service data exploration and visualization capabilities.
- Developed and maintained ETL workflows using AWS Glue and Python, ensuring the accuracy and reliability of data transformations.
- Optimized database performance in AWS Redshift by fine-tuning sort and distribution keys, resulting in a 25% reduction in query response time.
- Implemented real-time data processing solutions using AWS Kinesis and Apache Kafka, enabling timely insights into streaming data.
- Collaborated with data analysts to design and build a scalable data warehouse solution on AWS, facilitating efficient reporting and analysis.
- Provided mentoring and guidance to junior data engineers, fostering skill development and knowledge sharing within the team.
- Designed and developed scalable data ingestion pipelines using AWS Glue, handling high-volume data sources with complex transformations.
- Implemented serverless data processing workflows using AWS Lambda and Step Functions, reducing infrastructure costs by 40%.
- Optimized query performance in AWS Redshift through schema design and indexing strategies, resulting in faster data retrieval.
- Built real-time analytics solutions using AWS Kinesis and Elasticsearch, enabling immediate insights into streaming data.
- Collaborated with data scientists and business stakeholders to deliver data-driven projects, such as customer segmentation and predictive modeling.
- Architected and implemented highly scalable and fault-tolerant data processing pipelines on AWS using Glue, Lambda, and S3.
- Developed complex ETL processes with Apache Spark on AWS EMR, enabling efficient data transformation and loading into data lakes.
- Optimized performance of AWS Redshift clusters through query optimization and workload management techniques, resulting in faster data analysis.
- Built real-time streaming solutions using Kinesis Data Streams and Lambda, providing near-instantaneous data insights for time-critical applications.
- Collaborated with cross-functional teams to design and implement a comprehensive data architecture on AWS, ensuring data quality and reliability.
- Developed ETL processes using AWS Glue and Python, transforming and loading data from various sources into an AWS-based data warehouse.
- Implemented batch processing workflows on AWS Data Pipeline, ensuring the timely and accurate delivery of transformed data.
- Performed performance tuning on AWS Redshift by optimizing table design and distribution styles, improving query response times by 35%.
- Designed and implemented real-time data ingestion solutions using AWS Kinesis, enabling immediate processing and analysis of streaming data.
- Collaborated with software engineers to integrate data analytics capabilities into existing applications, enhancing the overall user experience.
- Developed and maintained data ingestion processes using AWS Glue, ensuring the availability of accurate and reliable data for analysis.
- Implemented serverless architectures with AWS Lambda, reducing infrastructure costs and enabling auto-scaling capabilities.
- Optimized query performance in AWS Redshift through index optimization and workload management techniques, resulting in faster data retrieval.
- Designed and implemented real-time analytics solutions using AWS Kinesis and Apache Spark Streaming, facilitating immediate data insights.
- Collaborated with data scientists to deploy machine learning models on AWS SageMaker, improving predictive accuracy and model deployment time.
Quantifying impact on your resume
<ul>
Addressing a lack of relevant AWS data engineer experience
Even if you lack direct AWS data engineer experience, you can still craft a compelling resume. Here's how:
- Highlight projects or publications that demonstrate your relevant skills or knowledge.
- Emphasize transferable skills, showcasing your adaptability and eagerness to learn.
- In your objective, outline your career aspirations and how they align with the company's goals.
- Consider a functional or hybrid resume format, focusing on skills over chronological experience.
Recommended reads:
Pro tip
Use the SOAR (Situation - Action - Results) method for each of your AWS data engineer experience bullets. Reflect on specific challenges you've addressed, the actions you took, and the outcomes. This approach also preps you for potential interview questions.
Highlighting essential hard and soft skills for your AWS data engineer resume
Your skill set is a cornerstone of your AWS data engineer resume.
Recruiters keenly evaluate:
- Your hard skills, gauging your proficiency with specific tools and technologies.
- Your soft skills, assessing your interpersonal abilities and adaptability.
A well-rounded candidate showcases a harmonious blend of both hard and soft skills, especially in a dedicated skills section.
When crafting your AWS data engineer skills section:
- List up to six skills that resonate with the job requirements and highlight your expertise.
- Feature a soft skill that encapsulates your professional persona, drawing from past feedback or personal reflections.
- Consider organizing your skills into distinct categories, such as "Technical Skills" or "Soft Skills."
- If you possess pivotal industry certifications, spotlight them within this section.
Crafting a comprehensive skills section can be daunting. To assist, we've curated lists of both hard and soft skills to streamline your resume-building process.
Top skills for your AWS data engineer resume:
AWS Glue
Amazon Redshift
Amazon S3
AWS Lambda
Apache Spark
SQL
Python
ETL Processes
Data Warehousing
Amazon RDS
Problem-Solving
Communication
Team Collaboration
Time Management
Analytical Thinking
Adaptability
Attention to Detail
Critical Thinking
Creativity
Project Management
Pro tip
Sometimes, basic skills mentioned in the job ad can be important. Include them in your resume, but don't give them too much space.
The importance of your certifications and education on your AWS data engineer resume
Pay attention to the resume education section . It can offer clues about your skills and experiences that align with the job.
- List only tertiary education details, including the institution and dates.
- Mention your expected graduation date if you're currently studying.
- Exclude degrees unrelated to the job or field.
- Describe your education if it allows you to highlight your achievements further.
Your professional qualifications: certificates and education play a crucial role in your AWS data engineer application.
They showcase your dedication to gaining the best expertise and know-how in the field.
Include any diplomas and certificates that are:
- Listed within the job requirements or could make your application stand out
- Niche to your industry and require plenty of effort to obtain
- Helping you prepare for professional growth with forward-facing know-how
- Relevant to the AWS data engineer job - make sure to include the name of the certificate, institution you've obtained it at, and dates
Both your certificates and education section need to add further value to your application.
That's why we've dedicated this next list just for you - check out some of the most popular AWS data engineer certificates to include on your resume:
Best certifications to list on your resume
Pro tip
If a particular certification is highly valued in the industry or by the company, consider highlighting it in your resume's headline.
Recommended reads:
Summary or objective: making your AWS data engineer resume shine
Start your resume with a strong summary or objective to grab the recruiter's attention.
- Use a resume objective if you're newer to the field. Share your career dreams and strengths.
- Opt for a resume summary if you have more experience. Highlight up to five of your top achievements.
Tailor your summary or objective for each job. Think about what the recruiter wants to see.
Resume summary and objective examples for a AWS data engineer resume
Enhancing your AWS data engineer resume with additional sections
Make your AWS data engineer resume truly distinctive by adding supplementary sections that showcase:
- Awards that underscore your industry recognition.
- Projects that bolster your application's relevance.
- Hobbies, if they can further your candidacy by revealing facets of your personality.
- Community involvement to highlight causes you champion.
Key takeaways
- Format your AWS data engineer resume for clarity and coherence, ensuring it aligns with the role.
- Highlight key sections (header, summary/objective, experience, skills, certifications) within your AWS data engineer resume.
- Quantify achievements and align them with skills and job requirements.
- Feature both technical and personal skills across your resume for a balanced portrayal.
